Greedy Approaches for Time Series Machine Learning Problems

Great news... My first research paper got proceeded at the 12th EvoMUSART conference which is a part of the EvoStar 2023 conference held in Czechia. Although the title of my published paper is "Improving Automatic Music Genre Classification Systems by Using Descriptive Statistical Features of Audio Signals", now I feel like I could name it as "A Greedy Approach for Music Genre Classification". Anyway I will put the abstraction of the paper here in this article. It's published by Springer on 1st April 2023. You can read the full paper in Springer. Or you can purchase the full EvoMUSART ebook also in Springer website. Update: The paper is available now on ACM digital library also.
Inspiration for this research
The paper "Improving Automatic Music Genre Classification Systems by Using Descriptive Statistical Features of Audio Signals" contains some findings of my final year research project, I did when I was a BSc undergraduate at the University of Colombo School of Computing.
First of all, let's learn what a music genre means. Music can be divided into many categories mainly based on rhythm, style, and cultural background. These categories are what we call music genres. Human perception of music is dependent on a variety of personal, cultural, and emotional aspects. Therefore, its genre classification results may avoid clear definition. So... the boundaries among music genres are fuzzy. That’s why we need automatic music genre classification systems.
Actually, the main goal of my final year research project was to find a way to classify Sinhala songs into music genres in order to reduce the search space of radio broadcast monitoring systems. This is the high level architecture of a radio broadcast monitoring system currently used in Sri Lanka.

And we are going to introduce this Sinhala songs' genre identification module for this system to reduce the search space of this matching service module. So.. it will index all songs in the DB by their music genre and then the matching module will have to match the radio broadcasted song with the songs only in the related music genre. The following diagram shows the proposed high level architecture for radio broadcast monitoring systems.
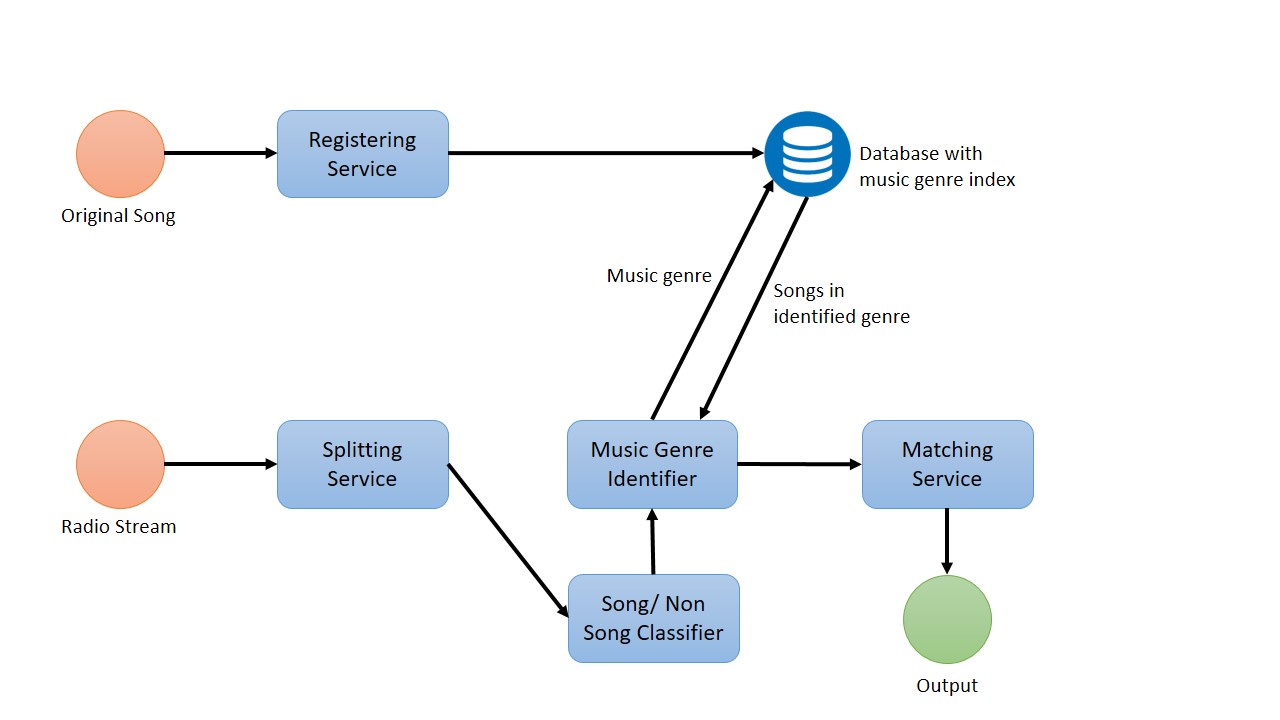
While doing that, we identified some research gaps in the Automatic music genre classification domain.
- As professional musicians say, they identify the music genre of a song by checking the tempo of the song and checking the pattern of the drum beat. But they haven’t scientifically proved that hypothesis.
- Current AMGC systems doesn't have any method to identify the key music genre of complex songs which contains multiple music genres within the song.
- And... There's a speed accuracy trade-off in AMGC systems found in the literature that makes them not suitable for increasing the efficiency of radio broadcast monitoring system. The best accuracy on GTZAN dataset is recorded as 94.5% by an ensemble model that combines a MLP model and a CNN max pooling LSTM model. The speed of the ensemble model with 2 SVMs introduced by Chathuranga is good for radio broadcast monitoring systems but its accuracy is recorded as 78% which is not enough.
So we followed an experimental research with quantitative data derived from qualitative data in the GTZAN dataset to address those research gaps. Let's go through the abstract of the paper.
Abstract of the paper
Automatic music genre classification (AMGC) systems are vital nowadays because the traditional music genre classification process is mostly implemented without following a universal taxonomy and the traditional process for audio indexing is prone to error. Various techniques to implement an automatic music genre classification system can be found in the literature but the accuracy and efficiency of those systems are insufficient to make them useful for practical scenarios such as identifying songs by the music genre in radio broadcast monitoring systems. The main contribution of this research is to increase the accuracy and efficiency of current automatic music genre classification systems with a comprehensive analysis of correlations between the descriptive statistical features of audio signals and the music genres of songs. A greedy approach for music genre identification is also introduced to improve the accuracy and efficiency of music genre classification systems and to identify the music genre of complex songs that contain multiple music genres. The approach, proposed in this paper, reported 87.3% average accuracy for music genre classification on the GTZAN dataset over 10 music genres.The Research Poster
You can find another summarized version of the paper in the following poster.

This is the poster I used for the poster presentation session at EvoMUSART 2023. All the key information are there and check the greedy approach section that played an important role in this work of research. Actually, I needed to focus on the greedy approach through this article just as I mention it in the title ;)
The Greedy Approach for Time Series Classification Problems
If each time series data has patterns that repeat over the time (ex: the rock drum beat of a rock song) and if we can classify the whole time series data into the correct label, then we don't need to analyze the whole data. A part of data analyzation is enough to identify the correct label. That's the basic idea of the greedy approach for time series data classification. You can read the full paper to understand how I used this trick to increase the speed and accuracy of AMGC systems.
However, the optimum time frame of songs is not experimented or tested in this research. Only an initiation for a greedy approach is proposed by considering only the first fifteen seconds of the song. So... it's open for future researches. And you can find more research ideas from the "Future Works" section of the paper.
Let's see why the greedy approach works better. This is the spectrogram of the last part of the baby song by Justin Bieber. There's a rap part in this song. If we consider the descriptive statistical features of the whole song, it will give features of a classical song. But if we consider a part of the song from the beginning, it will identify this as a pop song.

Here's another great example. This is a pop rap combination. If we consider a part of the song, we can identify it as a pop song or a hip-hop song. Otherwise it will give a wrong label.

Just a kind reminder... As this is a greedy approach this won't give the exactly correct answer sometimes and this won't work for all the cases ;)
More about the EvoStar and the EvoMUSART conferences
The EvoStar (Evo*) is organized by SPECIES, the Society for the Promotion of Evolutionary Computation in Europe and its Surroundings. This non-profit academic society is committed to promoting evolutionary algorithmic thinking, with inspiration of parallel algorithms derived from natural processes. It provides a forum for information and exchange. The EvoStar conference contains four co-located conferences in Bio-inspired Computation. Those four conferences are EuroGP, EvoApplications, EvoCOP and EvoMUSART. EvoStar 2023 was held from 12th April to 14th April 2023 at Brno University of Technology, Brno, Czech Republic.
- EuroGP - 26th European Conference on Genetic Programming
- EvoApplications - 26th European Conference on the Applications of Evolutionary and bio-inspired Computation
- EvoCOP - 23rd European Conference on Evolutionary Computation in Combinatorial Optimisation
- EvoMUSART - 12th International Conference (and 17th European event) on Evolutionary and Biologically Inspired Music, Sound, Art and Design
That's all for today... Thanks for reading and hope you will use our findings to continue your researches. So... let's meet with another research paper ;)

0 Comments
Post a Comment